
2000’li yıllarından başlarından itibaren etkileyici sonuçlar üreten modern yapay zeka algoritmalarının hemen hepsi “istatistiksel öğrenme” çerçevesinde veri kullanarak çalışır. Bunun ne demek olduğunu yine satranç örneği ile açıklayayım. Matematiksel modelleme ve mantık yaklaşımında satranç oyununda tahtadaki pozisonların sayısal olarak değerini belirleyen bir fonksiyon bulmaya çalışıyorduk. İstatistiksel öğrenme algoritmaları da tahtadaki pozisyonların değerini belirleyen bir fonksiyon kullanıyor ama bu fonksiyonu bilgisayara biz söylemiyoruz, özel durumları biz anlatmıyoruz. Onun yerine algoritmalar oynanmış milyarca oyunu değerlendirerek tahtadaki pozisyonların değerini belirleyen fonksiyonu istatistiksel yöntemlerle yaklaşık olarak buluyorlar.
Modelleme yöntemi fonksiyonları insanların akıl yürüterek bulması ile çalışıyor. İstatistiksel yöntemlerde ise veri toplayarak (ustalar arasında oynanmış oyunlar gibi) fonksiyonun girdi ve çıktılarını buluyoruz, sonra da olasılıksal yöntemlerle bu fonksiyonun ne olabileceğini bilgisayarlar hesaplıyor.
Satranç örneğindeki hesaplar oldukça karışık, daha basit bir örnek olarak
| 1 | 2 | 3 | 4 | 5 |
| 2,3 | 4,8 | 7,7 | 11,2 | ? |
sorusuna bakalım. Sayılar 2, 5, 8, 11, diye gitseydi, beşinci sayının 14 olması gerektiğine hemen karar verirdik1. Bizim örneğimizde bir miktar belirsizlik var, tam olarak y = 3x – 1 (buna basitçe x=1 iken 2’den başlayıp x arttıkça üçer üçer artan sayılar olarak bakabiliriz) doğrusal fonksiyonuna oturmuyor verimiz. Yine de beşinci sayıyı 14 olarak tahmin etmek oldukça makul görünüyor.
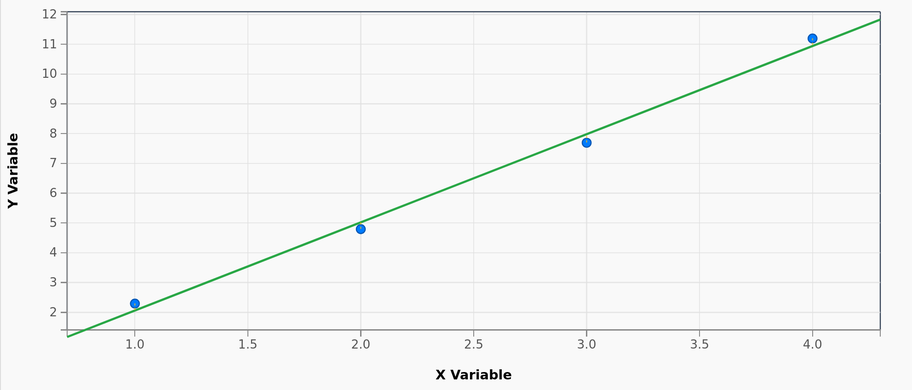
Bu tahmini makul yapan şey, gerçek veriyle “modelimizin” tahminleri arasındaki farkın oldukça küçük olması. Girdileri ve çıktıları içeren veriye (ground truth) bakarak bir algoritmanın “y=3x – 1” modelini bulması için öncelikle modelin ne tip fonksiyonlar olabileceğini kısıtlamak gerekli.
Yapay zekada “karar ağaçları”, “yapay sinir ağları” gibi terimler temelde öğrenilecek modelin nasıl bir fonksiyon olduğunu ifade eder. Basit örneğimizde modeli doğrusal fonksiyonlar olarak seçebiliriz. Veriye en iyi uyan modeli bulmak y = ax + b biçiminde olan fonksiyonlar içerisinde hangi a ve b değerlerini seçtiğimizde hatanın (gerçek çıktılar ve model tahminleri arasındaki fark) en küçük olacağını bulmaya denk gelir.
Kalem kağıtla soruyu incelediğimizde modelin hatasının a ve b parametrelerine bağlı bir fonksiyon olduğunu görürüz, buna hata fonksiyonu (loss function) denir. Soru böylelikle hata fonksiyonunu en küçük yapan a ve b parametrelerini bulma sorusuna dönüşür. Bunu da yinelemeli optimizasyon teknikleriyle çözeriz. Rastgele a ve b değerlerinden başlayıp hatayı hesaplarız, sonra adım adım bu hatayı azaltacak yönde parametreleri değiştiririz2. Parametreleri hatayı azaltacak biçimde değiştiren her bir adıma eğitim bölümü (training episode) denir. Bir süre sonra hata artık azalmamaya başlar, o zaman eğitimi durduruz.
Modern yapay zeka algoritmalarımızın hepsi benzer biçimde çalışır. 100 milyar parametreli bir yapay zeka modeli temelde 100 milyar parametreye bağlı bir fonksiyondur. Yapay zeka modeli eğitmek de girdi ve çıktıları içeren bir veriye bakarak, çıktıları en az hata ile tahmin eden parametreleri adım adım bulmaktır.
İstatistiksel öğrenme temelli algoritmaların, matematiksel modelleme ve mantığa göre en önemli avantajı alan uzmanlığına duyulan ihtiyacı ortadan kaldırmaları. Bilgisayara “vezir filden daha değerlidir” ya da “oyun sonu böyle oynanır” demenize gerek kalmıyor. Öte yandan istatistiksel öğrenme algoritmaları veriye muhtaç ve elde ettiğiniz sonuçların kalitesi verinin ne kadar kaliteli olduğuna bağlı. Acemi oyuncuların oynadığı birkaç yüz oyunla eğitilmiş bir yapay zeka algoritmasının iyi satranç oynaması mümkün değil.
Bu algoritmaların bir diğer önemli problemi de ne öğrendiklerini çoğunlukla bilemiyor olmamız. Algoritmalarımızın satranç oynamayı eski oyunlara bakarak nasıl öğrendiğini biliyoruz ama öğrendikleri şeyin – yani tahtadaki pozisyonların değerini hesaplayan fonksiyonun- ne olduğunu bilmiyoruz. Burada bilmemekten kastımız bir belirsizlik hali ya da fonksiyonun değerlerini yazamamak değil. Her bir modelin parametrelerini ve bunların nasıl biraraya geldiğinin kurallarını biliyoruz ama insan zekası ve anlayışı için milyarlarca parametreye bağlı karmaşık bir fonksiyonun formülünü yazmak bir “açıklama” değil. İnsan zekası “vezir filden değerlidir” gibi yüksek seviye açıklamalarla çalışıyor.
- Bu tip sorular bir açıdan manasız. İlk beş sayının üçer üçer artması sonraki sayının da aynı örüntüyü devam ettirmesini gerektirmez. Bir açıdan da manalı çünkü her zaman değilse bile pek çok durumda yanıt doğru çıkıyor. ↩︎
- Bu genel olarak optimizasyon alanının konusudur. En bilindik yöntemi “gradient descent”, kalkülüs derslerindeki türevin bir uygulamasıdır. ↩︎
Leave a Reply