
Elimizde veri varsa istatistiksel öğrenmeyle pek çok problemi çözebiliyoruz. 2000’lerden itibaren veriye “yeni petrol” muamelesi yapılmasının sebebi bu.
Fakat bazen çözmek istediğimiz probleme ait veri olmaz. Örneğin yürüyen bir insansı robot yapmak istediğinizde, engebeli bir zeminde hangi motorun hangi hızla ne kadar süreyle hareket etmesi gerektiğine dair bir veri yoktur. İnsanların hareketini modelleyerek de en fazla “robot gibi” hareket eden beceriksiz robotlar yapabiliyoruz.
Bu durumda imdadımıza fizik kurallarını büyük incelikle uygulayabilen bilgisayar simülasyonları yetişiyor. Bir sanal robotu böyle bir simülasyon programının içerisine yerleştirip, “A noktasından B noktasına düşmeden git.” diyebiliriz. Tabii biz git dedik diye gidebilecek değil ama bu deneyi milyarlarca kere farklı şekillerde yapma şansımız var. Robot her bir denemede hasbelkader de olsa başarılı giden kısımları ucuca ekleyerek “öğrenmeyi” başarırsa, yürüyebilir. Bu yaklaşımın adı pekiştirmeli öğrenme (reinforcement learning).
Evrimsel süreçlerden esinlenen pekiştirmeli öğrenmenin temel yaklaşımı, ortam (environment) ile etkileşen bir unsurun (agent) aldığı ödülle (reward) her an en iyi hareketi (action) bulmaya çalışmasıdır 1.
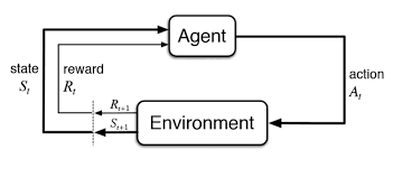
Robot örneğinde düşünecek olursak; unsur robot, çevre fiziksel dünya simülasyonu, ödül fonksiyonu düşmeden gidilen mesafe, hareket ise eklem motorlarının hızıdır.
Satranç örneğinde de bu yaklaşımı kullabiliriz. Rastgele oynayan algoritmaları birbiri ile oynatıp, kazanan ve kazanma şansını arttıran algoritmaları seçe seçe çok iyi satranç oynayan bir yapay zeka modeli yapmak mümkün.
Go oyunu yakın zamana kadar yapay zekayla çözemediğimiz problemlerden birisiydi. Satrançtan çok daha fazla farklı durum içerdiği için neredeyse umutsuz vaka olarak görülüyordu. Matematiksel modellemeler de, insanların kendi aralarında oynadıkları oyunlarla eğitmek de bir işe yaramıyordu. 2015 yılında Google’ın geliştirdiği AlphaGo, pekiştirmeli öğrenme tekniğiyle başarı kazandı. Bu modeller iki yıl içinde insan becerisinin çok üzerinde bir seviyeye (çevrimiçi bir turnuvada insanlara karşı 60-0) ulaştı. 3 yıl gibi bir zaman içerisinde “bilgisayarın insanı yenmesi imkansız”dan, “insanın bilgisayarı yenmesi imkansız”a geldik.
- Yapay zeka bağlamında agent terimi için “vekil” kelimesi de öneriliyor. Unsura da vekile de çok ısınamadım. ↩︎
Leave a Reply